Que sont les AprilTags?

Les AprilTags sont un système d’étiquettes visuelles développé par des chercheurs de l’Université du Michigan visant à fournir une localisation d’emplacement à basse consommation de ressources et haute précision adaptée à plusieurs applications.
Additional information about the tag system and its creators can be found on their website. This document attempts to summarize the content for FIRST robotics related purposes.
Application en FRC
Dans le contexte de la FRC, les AprilTags sont utiles pour aider votre robot à savoir où il se trouve sur le terrain, afin qu’Il puisse s’aligner avec les positions de buts.
Les AprilTags sont développées depuis 2011 et se sont raffinées avec les années, afin d’augmenter leur robustesse et la vitesse de détection.
Starting in 2023, FIRST is providing a number of tags, scattered throughout the field, each at a known pose.
What is the 36h11 family?
The AprilTag library implementation defines standards on how sets of tags should be designed. Some of the possible tag families are described here.
Starting from 2024, FIRST has chosen the 36h11 family. This family of tags is made of a 6x6 grid of pixels, each representing one bit of information. An additional black and white border must be present around the outside of the bits.
Bien qu’il y ait \(2^{36} = 68,719,476,736\) étiquettes théoriquement possibles, seules 587 sont réellement utilisées. Celles-ci sont choisies pour:
Être robustes contre le basculement de bit (ex: problèmes où le bit a sa couleur identifiée incorrectement).
Ne pas contenir de motifs géométriques « simples » qui pourraient se trouver sur des choses qui ne sont pas des cibles (ex: carrés, lignes, etc…).
S’assurer que le motif géométrique est assez asymétrique que vous pouvez toujours savoir quel côté pointe vers le haut.
Toutes les étiquettes seront imprimées de sorte que le « corps » principal de l’étiquette mesure 6,5 pouces de longueur.

Pour utilisation à la maison, les fichiers d’étiquette peuvent êtres imprimés et placés autour de votre aire de pratique. Fixez les sur un support rigide afin que les étiquettes restent plate, puisque l’algorithme de vision assume que l’étiquette est plate.
Support Logiciel
The main repository for the source code that detects and decodes AprilTags is located here.
WPIlib a ramifié la bibliothèque afin d’ajouter des nouvelles fonctionnalités pour la FRC. Entre autres:
Compiler le code source pour des cibles FRC courantes, incluant le roboRIO et Raspberry Pi.
Ajouter un support Java Native Interface (JNI) pour permettre l’invocation de ses fonctionnalités depuis Java
Support de publication Gradle et Maven
Technique de calcul
Bien que la plupart des équipes FRC ne devraient pas avoir à implémenter leur propre code pour identifier les AprilTags dans une image de caméra, il est utile de connaître les bases du fonctionnement des bibliothèques sous-jacentes.

Une image d’une caméra est simplement une liste de valeurs correspondant à la couleur et la luminosité de chaque pixel.

La première étape est de convertir l’image en tons de gris (luminosité seulement). L’information des couleurs n’est pas nécessaire pour détecter les étiquettes en noir et blanc.

La prochaine étape est de convertir l’image vers une résolution plus basse. Travailler avec moins de pixels aide l’algorithme à travailler plus vite. L’image en pleine résolution sera utilisée plus tard pour raffiner les estimations préliminaires.

Un algorithme de seuil adaptatif est exécuté afin de classifier chacun des pixels en « définitivement clair », « définitivement foncé » ou « incertain ».
Le seuil est calculé en regardant la luminosité du pixel comparé à celle du voisinage des pixels.

Ensuite, les pixels connus sont regroupés ensemble. Tout les groupes trop petits pour être une partie significative d’une étiquette sont supprimés.

Un algorithme pour associer un quadrilatère à chaque groupe est maintenant exécuté:
Identifier les « coins » probables par les pixels qui sont des valeurs aberrantes dans les deux dimensions.
Itérer au travers de toutes les combinaison possibles de coins, tout en évaluant l’appartenance à chaque fois.
Choisir le quadrilatère avec le meilleur ajustement
Compte tenu de l’ensemble de tout les quadrilatères, on identifie un sous-ensemble de quadrilatères qui est probablement une étiquette.
Un seul grand quadrilatère extérieur avec plusieurs quadrilatères intérieurs est sûrement un bon candidat.
Si tout s’est bien passé jusqu’ici, il nous reste une région de pixels à quatre côtés qui est sûrement une étiquette valide.

Maintenant que nous avons ai moins une région de pixels que nous croyons être un AprilTag valide, nous devons identifier l’étiquette que nous regardons. Cela est fait en « décodant » le motif de carrés clairs et foncés à l’intérieur.
Calculer les coordonnées attendues des pixels intérieurs où le centre de chaque bit devrait être
Marquer chaque emplacement en tant que « 1 » ou « 0 » en comparant l’intensité des pixels à un seuil
Trouver l’identifiant d’étiquette qui correspond de près avec ce qui a été vu dans l’image, en permettant une erreur d’un ou deux bits.
Il est possible qu’il n’y ait aucun identifiant d’étiquette valide qui correspond à l’étiquette suspectée. Dans ce cas, le processus de décodage s’arrête.

Maintenant que nous avons un identifiant d’étiquette pour la région de pixels, nous devons faire quelque chose d’utile avec.
Pour la plupart des applications en FRC, nous nous soucions de savoir la localisation précise des coins de l’étiquette, ou son centre. Dans les deux cas, nous nous attendons à ce que l’opération de diminution de la résolution que nous avons effectué au débit ait déformé l’image et nous voulons renverser ces effets.
L’algorithme pour faire cela est:
Utiliser la position de l’étiquette détectée pour définir une région d’intérêt dans l’image de résolution originale
Calculer la pente à des points prédéfinis dans la région d’intérêt pour détecter où l’image transitionne nettement entre le blanc et le noir
Utiliser ces mesures de pente pour rapidement réajuster un quadrilatère extérieur à la pleine résolution
Utiliser la géométrie pour calculer le centre exact du quadrilatère réajusté
Notez que cette étape est optionnelle et peut être ignorée pour un calcul plus rapide de l’image. Cependant, l’ignorer peut introduire des erreurs significative dans le comportement de votre robot, dépendamment de la manière que vous utilisez les sorties des étiquettes.
Utilisation
Alignement 2D
Une stratégie simple pour utiliser les cibles est de bouger le robot jusqu’à ce que la cible soit centrée dans l’image. Supposant que le terrain et le robot sont construits d’une manière que les pièces de jeu, la position du but, la cible de vision et la caméra sont alignés, cette méthode devrait être une méthode simple pour aligner le robot à la position de pointage.
En utilisant une caméra, identifiez le « centroïde » des AprilTags en vue. Si l’identifiant d’étiquette est correct, appliquez des commandes de conduite pour tourner le robot vers la gauche ou la droite jusqu’à ce que l’étiquette soit centrée dans l’image.
Cette méthode ne requiert pas de calibration ou de performer l’étape d’homographie.
Alignement 3D

A more advanced usage of AprilTags is to use their corner locations to help perform pose estimation.
Des AprilTags sont recherchés dans chaque image en utilisant l’algorithme décrit sur cette page. En utilisant des inférences sur la manière que la lentille de la caméra déforme le monde 3d en un tableau de pixels 2d dans la caméra, une estimation de la position de la caméra en relation avec l’étiquette est calculée. Une bonne calibration de la caméra est requise pour que les estimations sur le comportement de sa lentille soient précises.
L’identifiant de l’étiquette est aussi décodé depuis l’image. Compte tenu de chaque identifiant d’étiquette, la position de l’étiquette sur le terrain peut être recherchée.
Sachant la position de l’étiquette sur le terrain ainsi que la position de la caméra en relation avec l’étiquette, les classes de géométrie 3D peuvent être utilisées pour estimer la position de la caméra sur le terrain.
Si la positon de la caméra sur le robot est connue, la position du robot sur le terrain peut aussi être estimée.
Ces estimations peuvent être incorporées dans les classes d’estimation de pose de la WPILib.
Ambiguïté 2D vers 3D
Le processus de traduire les quatre coins connus de la cible dans l’image (en deux dimension) en une position réelle relative à la caméra (en trois dimensions) est intrinsèquement ambiguë. Cela est pour dire qu’il y a plusieurs positions réelles qui résultent en les coins cibles étant aux mêmes endroits dans l’image de la caméra.
Les humains peuvent souvent utiliser l’éclairage ou les indices en arrière-plan pour comprendre comment les objets sont orientés dans l’espace. Cependant, les ordinateurs n’ont pas ce bienfait. Ils peuvent être confus par des cibles similaires:



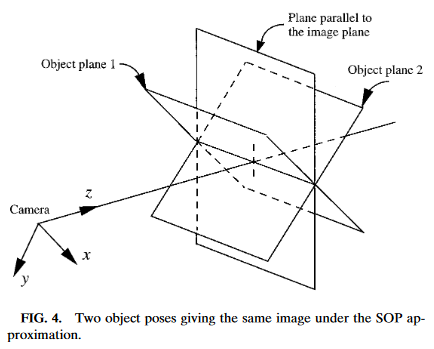
Résoudre quelle position est « correcte » peut être fait de quelques manières différentes:
Use your odometry history from all sensors to pick the pose closest to where you expect the robot to be.
Rejeter les poses très improbables (ex : hors du périmètre du terrain, ou en l’air)
Ignorer les estimations de poses qui sont très proche l’une de l’autre (et difficile à différencier)
Utiliser plusieurs caméras pour regarder la même cible afin qu’au moins une caméra puisse générer une assez bonne estimation
Regarder plusieurs cibles à la fois, en utilisant chacune pour générer plusieurs estimations de pose. Rejeter les estimations externes, en utilisant celles qui sont regroupées fermement ensemble.
Paramètres ajustables
Decimation Factor modifie à quel point l’image est dé-échantillonnée avant le traitement. L’augmenter accroîtra la vitesse de détection, au coût de ne pas voir les étiquettes qui sont éloignées.
Blur applique un lissage à l’image en entrée afin de réduire le bruit, ce qui accroît la vitesse de correspondance entre les pixels et les quadrilatères, au coût de la précision. Pour la plupart des caméras, ceci peut être laissé à zéro.
Threads changent le nombre de processus parallèles que l’algorithme utilise afin de traiter l’image. Certaines étapes peuvent êtres accélérées en permettant le multitraitement. En général, vous voudrez ce paramètre à peu près égal au nombre de cœurs physiques dans votre processeur, moins le nombre de cœurs qui seront utilisés dans d’autres tâches de traitement.
Detailed information about the tunable parameters can be found here.
Pour en savoir plus
Les trois versions majeures d’AprilTags sont décrites dans trois papiers académiques. Il est recommandé de les lire en ordre, puisque chacun ajoute au précédent: