Durum denetleyicisi ve Kalman Filtreleri
Durum gözlemcileri, sistemin doğru state nu tahmin etmek için bir sistemin davranışı ve harici ölçümler hakkındaki bilgileri birleştirir. Doğrusal sistemler için kullanılan yaygın bir gözlemci Kalman Filtresidir. Kalman filtreleri diğerlerine göre avantajlıdır filters, bir sistemin durumunu en iyi şekilde tahmin etmek için sistemin durum-uzay modeliyle bir veya daha fazla sensörden alınan ölçümleri birleştirir.
Bu görüntü, çeşitli farklı filtrelerden geçen zaman içindeki dönenteker hızı ölçümlerini gösterir. İyi ayarlanmış bir Kalman filtresinin dönerteker dönüşü sırasında hiçbir ölçüm gecikmesi göstermediğini ve gürültülü verileri hala reddederken ve toplar içinden geçerken rahatsızlıklara hızlı tepki verdiğini unutmayın. Filtrelerle ilgili daha fazla bilgi filters sectionbulunabilir.

Gauss Fonksiyonları
Kalman filters utilize a Gaussian distribution to model the noise in a process [1]. In the case of a Kalman filter, the estimated state of the system is the mean, while the variance is a measure of how certain (or uncertain) the filter is about the true state.
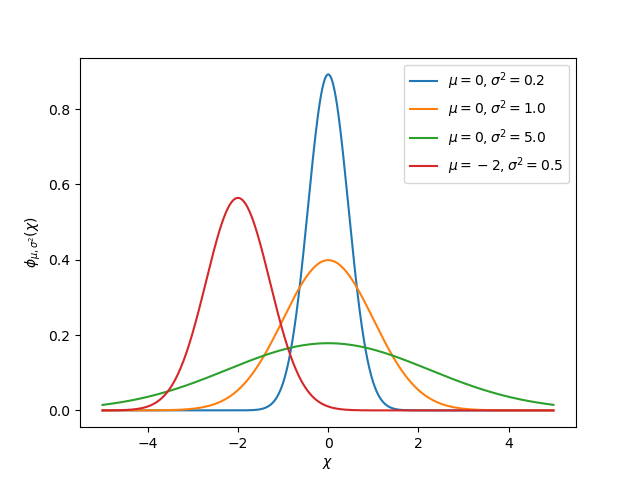
Varyans ve kovaryans fikri, bir Kalman filtresinin işlevinin merkezinde yer alır. Kovaryans, iki rastgele değişkenin nasıl ilişkilendirildiğinin bir ölçüsüdür. Tek durumlu bir sistemde kovaryans matrisi basitçe \(\mathbf{\text{var}(x_1)}\) veya varyansı içeren bir matristir \(\mathbf{\text{var}(x_1)}\) durum \(x_1\). Bu varyansın büyüklüğü, mevcut durum tahminini açıklayan Gauss fonksiyonunun standart sapmasının karesidir. Kovaryans için nispeten büyük değerler gürültülü verileri gösterebilirken, küçük kovaryanslar filtrenin tahmini konusunda daha emin olduğunu gösterebilir. Varyans veya kovaryans için “büyük” ve “küçük” değerlerin kullanılan temel birime göre olduğunu unutmayın - örneğin, eğer \(\mathbf{x_1}\) metre cinsinden ölçüldüyse, \(\mathbf{\text{cov}(x_1, x_1)}\) metre kare cinsinden olacaktır.
Kovaryans matrisleri aşağıdaki biçimde yazılır:
Kalman Filtreleri
Önemli
It is important to develop an intuition for what a Kalman filter is actually doing. The book Kalman and Bayesian Filters in Python by Roger Labbe provides a great visual and interactive introduction to Bayesian filters. The Kalman filters in WPILib use linear algebra to gentrify the math, but the ideas are similar to the single-dimensional case. We suggest reading through Chapter 4 to gain an intuition for what these filters are doing.
To summarize, Kalman filters (and all Bayesian filters) have two parts: prediction and correction. Prediction projects our state estimate forward in time according to our system’s dynamics, and correct steers the estimated state towards the measured state. While filters often perform both in the same timestep, it’s not strictly necessary – For example, WPILib’s pose estimators call predict frequently, and correct only when new measurement data is available (for example, from a low-framerate vision system).
Aşağıda, ayrık zamanlı bir Kalman filtresinin denklemleri gösterilmektedir:
Durum tahmini \(\mathbf{x}\), ile birlikte \(\mathbf{P}\), filtremizin sistemin gerçek durumuna ilişkin tahminini tanımlayan Gauss işlevinin ortalamasını ve kovaryansını açıklar.
Gürültü Kovaryans Matrislerinin İşlenmesi ve Ölçümü
The process and measurement noise covariance matrices \(\mathbf{Q}\) and \(\mathbf{R}\) describe the variance of each of our states and measurements. Remember that for a Gaussian function, variance is the square of the function’s standard deviation. In a WPILib, Q, and R are diagonal matrices whose diagonals contain their respective variances. For example, a Kalman filter with states \(\begin{bmatrix}\text{position} \\ \text{velocity} \end{bmatrix}\) and measurements \(\begin{bmatrix}\text{position} \end{bmatrix}\) with state standard deviations \(\begin{bmatrix}0.1 \\ 1.0\end{bmatrix}\) and measurement standard deviation \(\begin{bmatrix}0.01\end{bmatrix}\) would have the following \(\mathbf{Q}\) and \(\mathbf{R}\) matrices:
Error Covariance Matrix-Hata Kovaryans Matrisi
Hata kovaryans matrisi \(\mathbf{P}\), durum tahmininin kovaryansını açıklar \(\mathbf{\hat{x}}\). Gayri resmi olarak, \(\mathbf{P}\), tahmin edilen state hakkındaki kesinliğimizi tanımlar. Eğer \(\mathbf{P}\) büyükse, gerçek durum hakkındaki belirsizliğimiz büyüktür. Tersine, daha küçük elemanlara sahip \(\mathbf{P}\), gerçek durumumuz hakkında daha az belirsizlik anlamına gelir.
Modeli ileriye doğru yansıtırken, sistemin gerçek durumu hakkındaki kesinliğimiz azaldıkça \(\mathbf{P}\) artar.
Tahmin adımı
Tahminde, durum tahminimiz doğrusal sistem dinamiklerine göre güncellenir \(\mathbf{\dot{x} = Ax + Bu}\). Ayrıca, hata kovaryansımız \(\mathbf{P}\), işlem gürültü kovaryans matrisi \(\mathbf{Q}\) ile artar. Daha büyük \(\mathbf{Q}\) değerleri, hata kovaryansımızın \(\mathbf{P}\) daha hızlı büyümesini sağlayacaktır. Bu \(\mathbf{P}\), modeli ve ölçümleri ağırlıklandırmak için düzeltme adımında kullanılır.
Doğru adım
Doğru adımda, durum tahminimiz yeni ölçüm bilgilerini içerecek şekilde güncellenir. Bu yeni bilgi, Kalman kazancı \(\mathbf{K}\) tarafından \(\ mathbf{\hat {x}}\) ‘durum tahminine göre ağırlıklandırılır. \(\mathbf{K}\) ‘nın büyük değerleri gelen ölçümleri daha fazla ağırlıklandırırken, \(\mathbf{K}\) ‘nın daha küçük değerleri durum tahminimize daha fazla ağırlık verir. Çünkü \(\mathbf{K}\), \(\mathbf{P}\) ile ilgilidir, \(\mathbf{P}\) ‘nin daha büyük değerleri \(\mathbf{K}' 'yı arttıracaktır ve ölçümleri daha ağırlıklandıracaktır. Örneğin, uzun bir süre için bir filtre tahmin edilirse, büyük :math:\)mathbf{P}`, yeni bilgileri büyük ölçüde ağırlaştıracaktır.
Son olarak, hata kovaryansı \(\mathbf{P}\) durum tahminine olan güvenimizi artırmak için azalır.
Kalman Filtrelerini Ayarlama
WPILib’in Kalman Filtresi sınıflarının constructorları, doğrusal bir sistemi, işlem gürültüsü standart sapmalarının bir vektörünü ve ölçüm gürültüsü standart sapmalarını alır. Bunlar, köşegenleri her durum veya ölçümün standart sapmalarının veya varyanslarının karesiyle doldurarak \(\mathbf{Q}\) ve \(\mathbf{R}\) matrislerine dönüştürülür. Bir durumun standart sapmasını (ve dolayısıyla, \(\mathbf{Q}\) içindeki karşılık gelen girdisini) azaltarak, filtre gelen ölçümlere daha fazla güvenmeyecektir. Benzer şekilde, bir durumun standart sapmasını artırmak, gelen ölçümlere daha çok güvenecektir. Aynısı, ölçüm standart sapmaları için de geçerlidir - bir girişi azaltmak, filtrenin ilgili durum için gelen ölçüme daha fazla güvenmesini sağlarken, artması ölçüme olan güveni azaltacaktır.
48 // The observer fuses our encoder data and voltage inputs to reject noise.
49 private final KalmanFilter<N1, N1, N1> m_observer =
50 new KalmanFilter<>(
51 Nat.N1(),
52 Nat.N1(),
53 m_flywheelPlant,
54 VecBuilder.fill(3.0), // How accurate we think our model is
55 VecBuilder.fill(0.01), // How accurate we think our encoder
56 // data is
57 0.020);
5#include <numbers>
6
7#include <frc/DriverStation.h>
8#include <frc/Encoder.h>
9#include <frc/TimedRobot.h>
10#include <frc/XboxController.h>
11#include <frc/controller/LinearQuadraticRegulator.h>
12#include <frc/drive/DifferentialDrive.h>
13#include <frc/estimator/KalmanFilter.h>
14#include <frc/motorcontrol/PWMSparkMax.h>
15#include <frc/system/LinearSystemLoop.h>
16#include <frc/system/plant/DCMotor.h>
17#include <frc/system/plant/LinearSystemId.h>
18#include <units/angular_velocity.h>
48 // The observer fuses our encoder data and voltage inputs to reject noise.
49 frc::KalmanFilter<1, 1, 1> m_observer{
50 m_flywheelPlant,
51 {3.0}, // How accurate we think our model is
52 {0.01}, // How accurate we think our encoder data is
53 20_ms};
49 # The observer fuses our encoder data and voltage inputs to reject noise.
50 self.observer = wpimath.estimator.KalmanFilter_1_1_1(
51 self.flywheelPlant,
52 (3,), # How accurate we think our model is
53 (0.01,), # How accurate we think our encoder data is
54 0.020,
55 )