State Observers and Kalman Filters
State observers combine information about a system’s behavior and external measurements to estimate the true state of the system. A common observer used for linear systems is the Kalman Filter. Kalman filters are advantageous over other filters as they fuse measurements from one or more sensors with a state-space model of the system to optimally estimate a system’s state.
This image shows flywheel velocity measurements over time, run through a variety of different filters. Note that a well-tuned Kalman filter shows no measurement lag during flywheel spinup while still rejecting noisy data and reacting quickly to disturbances as balls pass through it. More on filters can be found in the filters section.

Gaussian Functions
Kalman filters utilize a Gaussian distribution to model the noise in a process [1]. In the case of a Kalman filter, the estimated state of the system is the mean, while the variance is a measure of how certain (or uncertain) the filter is about the true state.
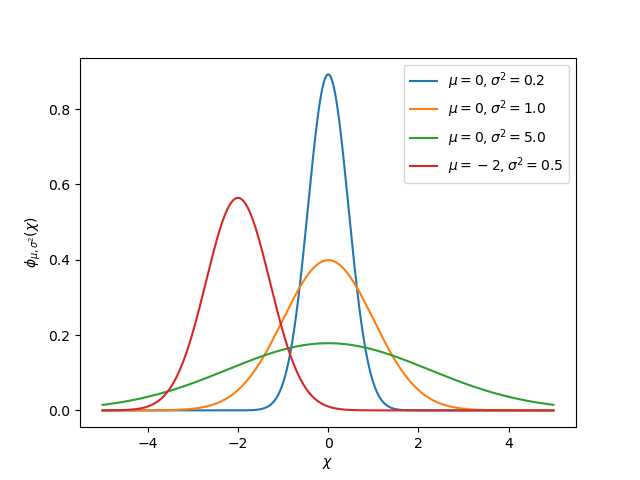
The idea of variance and covariance is central to the function of a Kalman filter. Covariance is a measurement of how two random variables are correlated. In a system with a single state, the covariance matrix is simply \(\mathbf{\text{cov}(x_1, x_1)}\), or a matrix containing the variance \(\mathbf{\text{var}(x_1)}\) of the state \(x_1\). The magnitude of this variance is the square of the standard deviation of the Gaussian function describing the current state estimate. Relatively large values for covariance might indicate noisy data, while small covariances might indicate that the filter is more confident about it’s estimate. Remember that «large» and «small» values for variance or covariance are relative to the base unit being used – for example, if \(\mathbf{x_1}\) was measured in meters, \(\mathbf{\text{cov}(x_1, x_1)}\) would be in meters squared.
Covariance matrices are written in the following form:
Kalman Filters
Importante
It is important to develop an intuition for what a Kalman filter is actually doing. The book Kalman and Bayesian Filters in Python by Roger Labbe provides a great visual and interactive introduction to Bayesian filters. The Kalman filters in WPILib use linear algebra to gentrify the math, but the ideas are similar to the single-dimensional case. We suggest reading through Chapter 4 to gain an intuition for what these filters are doing.
To summarize, Kalman filters (and all Bayesian filters) have two parts: prediction and correction. Prediction projects our state estimate forward in time according to our system’s dynamics, and correct steers the estimated state towards the measured state. While filters often perform both in the same timestep, it’s not strictly necessary – For example, WPILib’s pose estimators call predict frequently, and correct only when new measurement data is available (for example, from a low-framerate vision system).
The following shows the equations of a discrete-time Kalman filter:
The state estimate \(\mathbf{x}\), together with \(\mathbf{P}\), describe the mean and covariance of the Gaussian function that describes our filter’s estimate of the system’s true state.
Process and Measurement Noise Covariance Matrices
The process and measurement noise covariance matrices \(\mathbf{Q}\) and \(\mathbf{R}\) describe the variance of each of our states and measurements. Remember that for a Gaussian function, variance is the square of the function’s standard deviation. In a WPILib, Q, and R are diagonal matrices whose diagonals contain their respective variances. For example, a Kalman filter with states \(\begin{bmatrix}\text{position} \\ \text{velocity} \end{bmatrix}\) and measurements \(\begin{bmatrix}\text{position} \end{bmatrix}\) with state standard deviations \(\begin{bmatrix}0.1 \\ 1.0\end{bmatrix}\) and measurement standard deviation \(\begin{bmatrix}0.01\end{bmatrix}\) would have the following \(\mathbf{Q}\) and \(\mathbf{R}\) matrices:
Error Covariance Matrix
The error covariance matrix \(\mathbf{P}\) describes the covariance of the state estimate \(\mathbf{\hat{x}}\). Informally, \(\mathbf{P}\) describes our certainty about the estimated state. If \(\mathbf{P}\) is large, our uncertainty about the true state is large. Conversely, a \(\mathbf{P}\) with smaller elements would imply less uncertainty about our true state.
As we project the model forward, \(\mathbf{P}\) increases as our certainty about the system’s true state decreases.
Predict step
In prediction, our state estimate is updated according to the linear system dynamics \(\mathbf{\dot{x} = Ax + Bu}\). Furthermore, our error covariance \(\mathbf{P}\) increases by the process noise covariance matrix \(\mathbf{Q}\). Larger values of \(\mathbf{Q}\) will make our error covariance \(\mathbf{P}\) grow more quickly. This \(\mathbf{P}\) is used in the correction step to weight the model and measurements.
Correct step
In the correct step, our state estimate is updated to include new measurement information. This new information is weighted against the state estimate \(\mathbf{\hat{x}}\) by the Kalman gain \(\mathbf{K}\). Large values of \(\mathbf{K}\) more highly weight incoming measurements, while smaller values of \(\mathbf{K}\) more highly weight our state prediction. Because \(\mathbf{K}\) is related to \(\mathbf{P}\), larger values of \(\mathbf{P}\) will increase \(\mathbf{K}\) and more heavily weight measurements. If, for example, a filter is predicted for a long duration, the large \(\mathbf{P}\) would heavily weight the new information.
Finally, the error covariance \(\mathbf{P}\) decreases to increase our confidence in the state estimate.
Tuning Kalman Filters
WPILib’s Kalman Filter classes” constructors take a linear system, a vector of process noise standard deviations and measurement noise standard deviations. These are converted to \(\mathbf{Q}\) and \(\mathbf{R}\) matrices by filling the diagonals with the square of the standard deviations, or variances, of each state or measurement. By decreasing a state’s standard deviation (and therefore its corresponding entry in \(\mathbf{Q}\)), the filter will distrust incoming measurements more. Similarly, increasing a state’s standard deviation will trust incoming measurements more. The same holds for the measurement standard deviations – decreasing an entry will make the filter more highly trust the incoming measurement for the corresponding state, while increasing it will decrease trust in the measurement.
48 // The observer fuses our encoder data and voltage inputs to reject noise.
49 private final KalmanFilter<N1, N1, N1> m_observer =
50 new KalmanFilter<>(
51 Nat.N1(),
52 Nat.N1(),
53 m_flywheelPlant,
54 VecBuilder.fill(3.0), // How accurate we think our model is
55 VecBuilder.fill(0.01), // How accurate we think our encoder
56 // data is
57 0.020);
5#include <numbers>
6
7#include <frc/DriverStation.h>
8#include <frc/Encoder.h>
9#include <frc/TimedRobot.h>
10#include <frc/XboxController.h>
11#include <frc/controller/LinearQuadraticRegulator.h>
12#include <frc/drive/DifferentialDrive.h>
13#include <frc/estimator/KalmanFilter.h>
14#include <frc/motorcontrol/PWMSparkMax.h>
15#include <frc/system/LinearSystemLoop.h>
16#include <frc/system/plant/DCMotor.h>
17#include <frc/system/plant/LinearSystemId.h>
18#include <units/angular_velocity.h>
48 // The observer fuses our encoder data and voltage inputs to reject noise.
49 frc::KalmanFilter<1, 1, 1> m_observer{
50 m_flywheelPlant,
51 {3.0}, // How accurate we think our model is
52 {0.01}, // How accurate we think our encoder data is
53 20_ms};
49 # The observer fuses our encoder data and voltage inputs to reject noise.
50 self.observer = wpimath.estimator.KalmanFilter_1_1_1(
51 self.flywheelPlant,
52 (3,), # How accurate we think our model is
53 (0.01,), # How accurate we think our encoder data is
54 0.020,
55 )