What Are AprilTags?¶

AprilTags are a system of visual tags developed by researchers at the University of Michigan to provide low overhead, high accuracy localization for many different applications.
Additional information about the tag system and its creators can be found on their website. This document attempts to summarize the content for FIRST robotics related purposes.
Application to FRC¶
In the context of FRC, AprilTags are useful for helping your robot know where it is at on the field, so it can align itself to some goal position.
AprilTags have been in development since 2011, and have been refined over the years to increase the robustness and speed of detection.
Starting in 2023, FIRST is providing a number of tags, scattered throughout the field, each at a known pose.
What is the 36h11 family?
The AprilTag library implementation defines standards on how sets of tags should be designed. Some of the possible tag families are described here.
Starting from 2024, FIRST has chosen the 36h11 family. This family of tags is made of a 6x6 grid of pixels, each representing one bit of information. An additional black and white border must be present around the outside of the bits.
While there are \(2^{36} = 68,719,476,736\) theoretical possible tags, only 587 are actually used. These are chosen to:
Be robust against some bit flips (IE, issues where a bit has its color incorrectly identified).
Not involve “simple” geometric patterns likely to be found on things which are not tags. (IE, squares, stripes, etc.)
Ensure the geometric pattern is asymmetric enough that you can always figure out which way is up.
All tags will be printed such that the tag’s main “body” is 6.5 inches in length.

For home usage, tag files may be printed off and placed around your practice area. Mount them to a rigid backing material to ensure the tag stays flat, as the processing algorithm assumes the tags are flat.
Software Support¶
The main repository for the source code that detects and decodes AprilTags is located here.
WPILib has forked the repository to add new features for FRC. These include:
Building the source code for common FRC targets, including the roboRIO and Raspberry Pi.
Adding Java Native Interface (JNI) support to allow invoking its functionality from Java
Gradle & Maven publishing support
Todo
Work in this library is still ongoing, this list may change in the future.
Processing Technique¶
While most FRC teams should not have to implement their own code to identify AprilTags in a camera image, it is useful to know the basics of how the underlying libraries function.

An image from a camera is simply an array of values, corresponding to the color and brightness of each pixel.

The first step is to convert the image to a grey-scale (brightness-only) image. Color information is not needed to detect the black-and-white tags.

The next step is to convert the image to a lower resolution. Working with fewer pixels helps the algorithm work faster. The full-resolution image will be used later to refine early estimates.

An adaptive threshold algorithm is run to classify each pixel as “definitely light”, “definitely dark”, or “not sure”.
The threshold is calculated by looking at the pixel’s brightness, compared to a small neighborhood of pixels around it.

Next, the known pixels are clumped together. Any clumps which are too small to reasonably be a meaningful part of a tag are discarded.

An algorithm for fitting a quadrilateral to each clump is now run:
Identify likely “corner” candidates by pixels which are outliers in both dimensions.
Iterate through all possible combinations of corners, evaluating the fit each time
Pick the best-fit quadrilateral
Given the set of all quadralaterals, Identify a subset of quadrilaterals which is likely a tag.
A single large exterior quadrilateral with many interior quadrilateral is likely a good candidate.
If all has gone well so far, we are left with a four-sided region of pixels that is likely a valid tag.

Now that we have one or more regions of pixels which we believe to be a valid AprilTag, we need to identify which tag we are looking at. This is done by “decoding” the pattern of light and dark squares on the inside.
Calculate the expected interior pixel coordinates where the center of each bit should be
Mark each location as “1” or “0” by comparing the pixel intensity to a threshold
Find the tag ID which most closely matches what was seen in the image, allowing for one or two bit errors.
It is possible there is no valid tag ID which matches the suspect tag. In this case, the decoding process stops.

Now that we have a tag ID for the region of pixels, we need to do something useful with it.
For most FRC applications, we care about knowing the precise location of the corners of the tag, or its center. In both cases, we expect the resolution-lowering operation we did at the beginning to have distorted the image, and we want to undo those effects.
The algorithm to do this is:
Use the detected tag location to define a region of interest in the original-resolution image
Calculate the gradient at pre-defined points in the region of interest to detect where the image most sharply transitions between black to white
Use these gradient measurements to rapidly re-fit an exterior quadrilateral at full resolution
Use geometry to calculate the exact center of the re-fit quadrilateral
Note that this step is optional, and can be skipped for faster image processing. However, skipping it can induce significant errors into your robot’s behavior, depending on how you are using the tag outputs.
Usage¶
2D Alignment¶
A simple strategy for using targets is to move the robot until the target is centered in the image. Assuming the field and robot are constructed such that the gamepiece, scoring location, vision target, and camera are all aligned, this method should proved a straightforward method to automatically align the robot to the scoring position.
Using a camera, identify the centroid of the AprilTags in view. If the tag’s ID is correct, apply drivetrain commands to rotate the robot left or right until the tag is centered in the camera image.
This method does not require calibrating the camera or performing the homography step.
3D Alignment¶

Todo
Code examples coming soon!
A more advanced usage of AprilTags is to use their corner locations to help perform pose estimation.
Each image is searched for AprilTags using the algorithm described on this page. Using assumptions about how the camera’s lense distorts the 3d world onto the 2d array of pixels in the camera, an estimate of the camera’s position relative to the tag is calculated. A good camera calibration is required for the assumptions about its lens behavior to be accurate.
The tag’s ID is also decoded. from the image. Given each tag’s ID, the position of the tag on the field can be looked up.
Knowing the position of the tag on the field, and the position of the camera relative to the tag, the 3D geometry classes can be used to estimate the position of the camera on the field.
If the camera’s position on the robot is known, the robot’s position on the field can also be estimated.
These estimates can be incorporated into the WPILib pose estimation classes.
2D to 3D Ambiguity¶
The process of translating the four known corners of the target in the image (two-dimensional) into a real-world position relative to the camera (three-dimensional) is inherently ambiguous. That is to say, there are multiple real-world positions that result in the target corners ending up in the same spot in the camera image.
Humans can often use lighting or background clues to understand how objects are oriented in space. However, computers do not have this benefit. They can be tricked by similar-looking targets:



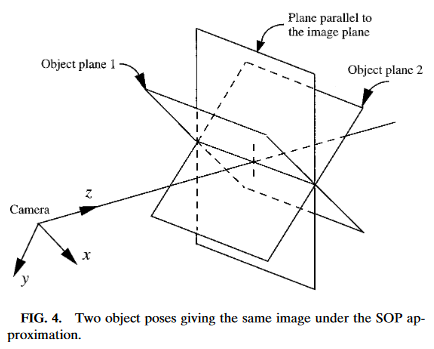
Resolving which position is “correct” can be done in a few different ways:
Use your odometry history from all sensors to pick the pose closest to where you expect the robot to be.
Reject poses which are very unlikely (ex: outside the field perimeter, or up in the air)
Ignore pose estimates which are very close together (and hard to differentiate)
Use multiple cameras to look at the same target, such that at least one camera can generate a good pose estimate
Look at many targets at once, using each to generate multiple pose estimates. Discard the outlying estimates, use the ones which are tightly clustered together.
Adjustable Parameters¶
Decimation factor impacts how much the image is down-sampled before processing. Increasing it will increase detection speed, at the cost of not being able to see tags which are far away.
Blur applies smoothing to the input image to decrease noise, which increases speed when fitting quads to pixels, at the cost of precision. For most good cameras, this may be left at zero.
Threads changes the number of parallel threads which the algorithm uses to process the image. Certain steps may be sped up by allowing multithreading. In general, you want this to be approximately equal to the number of physical cores in your CPU, minus the number of cores which will be used for other processing tasks.
Detailed information about the tunable parameters can be found here.
Further Learning¶
The three major versions of AprilTags are described in three academic papers. It’s recommended to read them in order, as each builds upon the previous: